












En la actualidad vivimos en una sociedad donde la gente tiene a tan solo unos pocos clicks, el acceso a toneladas de información. Poseemos dispositivos que se comunican con otros para intercambiar y generar información de todo tipo y ya son términos de nuestra vida diaria conceptos como IOT, Smart city, Cloud, Big data, etc.

Probablemente el que más hayas escuchado es el Big data. Pero… ¿Qué es realmente? El Big Data se podría definir como conjuntos de datos o combinaciones de conjuntos de datos cuyo tamaño, complejidad y velocidad de crecimiento dificultan su captura, gestión, procesamiento o análisis.
Actualmente representa un problema para muchas empresas cuyo volumen de datos ven crecer sin saber cómo explotarlo y gestionarlo. Uno de los factores más importantes que hay que tener en cuenta para lidiar con grandes volúmenes de datos, es la elección correcta de la base de datos. Existen de varios tipos pero los más importantes son:
— SQL: Myslq, Oracle, Postgress,etc.
— NoSQL: Elasticsearch, MongoDB, Redis, Cassandra, etc.
Lo ideal para este tipo de casos es utilizar una base de Datos NoSQL por los siguientes motivos:
— La información almacenada no requiere un formato o esquema definido.
— No garantizan ACID para mejorar el rendimiento y disponibilidad.
— Replicación y distribución.
— Permiten escalabilidad horizontal.
En IoTsens disponemos de una base de datos Elasticsearch para el almacenamiento y manipulación de los datos generados por la gran cantidad de dispositivos que comunican con nuestra plataforma. De entre todas las características de esta base de datos, las más remarcables son las siguientes:
— Es un motor de búsquedas basado en Apache Lucene.
— Estructura los datos mediante Inverted Index, lo que otorga una mayor rapidez a las búsquedas.
— Permite la distribución de los datos en distintos servidores.
— Posee un API REST mediante el cual se pueden recuperar e interactuar con los datos, además de gestionar la propia base de datos.
— Indexa documentos en formato JSON libre de schemas.
— Garantiza una alta disponibilidad de los datos, ya que es capaz de recuperarse automáticamente en caso de caída de uno o varios de los servidores donde están los datos.
— Mediante agregaciones es posible realizar operaciones para explotar los datos.
Dar los primeros pasos en Elasticsearch es simple y sólo conlleva una ligera curva de aprendizaje. No obstante, antes de empezar es aconsejable conocer bien la nomenclatura de algunos de los elementos básicos que lo componen:
— Cluster: Colección de nodos.
— Node: Servidor que forma parte de un cluster.
— Shard: Partición distribuida de la información debida a limitaciones de hardware.
— Index: «Equivale» a una base de datos en SQL,
— Type: «Equivale» a una tabla en SQL.
— Mapping: «Equivale» a un schema en SQL.
— Document: Unidad básica de información o el dato a guardar.
Una vez aprendidos los términos vamos a ver varios ejemplos prácticos sencillos mediante el uso del API.
Crear un Index:

Eliminar un Index:
![]()
Insertar un documento:

Recuperar el mismo documento:
![]()
Como puedes ver en los ejemplos anteriores, no conlleva mucha dificultad realizar operaciones básicas como la creación de un Index, almacenar un documento, recuperarlo, etc. No obstante, el potencial de Elastisearch reside en sus búsquedas avanzadas, las cuales permiten explotar sus datos de diversas maneras.
Un ejemplo de una consulta avanzada es el siguiente:
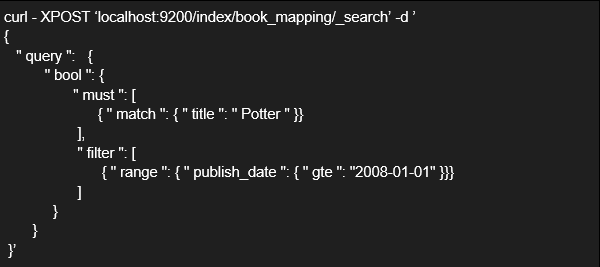
Además de permitir buscar elementos, elasticsearch ofrece la posibilidad de refinar los resultados de nuestras búsquedas e incluso realizar operaciones con ellos gracias a las agregaciones. Gracias a ellas podemos:
— Agrupar los resultados obtenidos en buckets.
— Existe la posibilidad de hacer operaciones con los datos agrupados y obtener nuevos datos.
— Pueden combinarse los diferentes tipos de agregaciones.
— Permiten realizar filtros más específicos.
A continuación voy a mostrar un ejemplo práctico para ver el uso y potencial de las agregaciones, donde el dueño de una librería quiere obtener el precio medio de los libros por género.
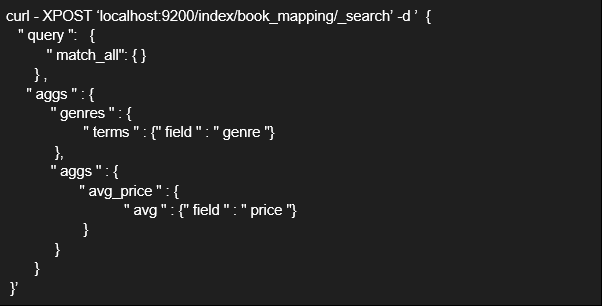
En estos últimos ejemplos, ha incrementado la complejidad moderadamente. Pero no te asustes, ni te desesperes. Con un poquito de paciencia y práctica se puede dominar y obtener grandes resultados para tu empresa o proyectos.
En IoTsens tenemos más de 2.500.000.000 documentos almacenados que ocupan 300 gigas de espacio. Diariamente se almacenan más de 9.000.000 documentos y somos capaces de recuperar, procesar y mostrar al usuario alrededor de 300.000 documentos (31Mb aprox) en unos 2.5-5 segundos.
Como puedes observar, con el uso de Elasticsearch hemos obtenido fantásticos resultados, pero además de nosotros, otras empresas como Tesco, LinkedIn, Foursquare, Facebook, Netflix, Dell, eBay, Wikipedia, The Guardian, The New York Times, Salesforce, Docker, Orange, Groupon y Eventbrite, también lo utilizan, dependiendo de ello parte de su éxito.
